Rozdíl mezi rychlým a sloučeným tříděním

Obsah
Algoritmy rychlého třídění a sloučení jsou založeny na algoritmu dělení a dobývání, který funguje docela podobným způsobem. Předchozí rozdíl mezi rychlým a sloučeným tříděním spočívá v tom, že v rychlém třídění se pro třídění použije otočný prvek. Na druhou stranu slučovací řazení nepoužívá k provedení třídění pivot.
Obě třídicí techniky, rychlé třídění a sloučené třídění jsou postaveny na metodě rozdělení a dobytí, ve které se sada prvků rozdělí a po přestavení spojí. Rychlé třídění obvykle vyžaduje více třídění než sloučené třídění pro třídění velké sady prvků.
-
- Srovnávací tabulka
- Definice
- Klíčové rozdíly
- Závěr
Srovnávací tabulka
| Základ pro srovnání | Rychlé řazení | Sloučit třídění |
|---|---|---|
| Rozdělení prvků v poli | Rozdělení seznamu prvků nemusí být nutně rozděleno na polovinu. | Pole je vždy rozděleno na polovinu (n / 2). |
| Nejhorší složitost případu | Na2) | O (n log n) |
| Funguje dobře | Menší pole | Funguje dobře v jakémkoli typu pole. |
| Rychlost | Rychlejší než jiné třídicí algoritmy pro malé soubory dat. | Stálá rychlost ve všech typech datových sad. |
| Další požadavek na úložný prostor | Méně | Více |
| Účinnost | Neefektivní pro větší pole. | Efektivnější. |
| Metoda třídění | Vnitřní | Externí |
Definice rychlého třídění
Rychlé řazení je všudypřítomný algoritmus třídění, protože je rychlý pro krátká pole. Sada prvků je opakovaně rozdělena na části, dokud není možné je dále rozdělit. Rychlé řazení je také známé jako třídění oddílů. Pro rozdělení prvků používá klíčový prvek (známý jako pivot). Jeden oddíl obsahuje ty prvky, které jsou menší než klíčový prvek. Jiný oddíl obsahuje ty prvky, které jsou větší než klíčový prvek. Prvky jsou rekurzivně tříděny.
Předpokládejme, že A je pole A, A, A, …… .., A z n čísla, které musí být tříděno. Algoritmus rychlého třídění sestával z následujících kroků.
- První prvek nebo libovolný náhodný prvek vybraný jako klíč předpokládá klíč = A (1).
- Ukazatel „low“ je umístěn na druhém a ukazatel „up“ je umístěn na posledním prvku pole, tj. Low = 2 a up = n;
- Důsledně zvyšujte ukazatel „low“ o jednu pozici, dokud (tlačítko A>).
- Neustále snižujte ukazatel „nahoru“ o jednu pozici, dokud (A <= klíč).
- Pokud je hodnota vyšší než nízká, vyměňte A s A.
- Opakujte kroky 3,4 a 5, dokud podmínka v kroku 5 selže (tj. Nahoru <= nízká), poté zaměňte A s klíčem.
- Pokud jsou prvky vlevo od klíče menší než klíč a prvky vpravo od klíče jsou větší než klíč, je pole rozděleno do dvou dílčích polí.
- Výše uvedený postup se opakovaně aplikuje na dílčí pole, dokud není celé pole seřazeno.

Výhody a nevýhody
To má dobré průměrné chování případu. Složitost běhu rychlého řazení je dobrá, protože je rychlejší než algoritmy, jako je řazení bublin, řazení a výběr. Je však složitý a velmi rekurzivní, proto není vhodný pro velká pole.
Definice slučovacího třídění
Sloučit třídění je externí algoritmus, který je také založen na strategii rozdělení a dobytí. Prvky se dělí na dílčí pole (n / 2) znovu a znovu, dokud nezůstane pouze jeden prvek, což významně zkracuje čas třídění. Pro uložení pomocného pole používá další úložiště. Sloučit třídění používá tři pole, kde dvě se používají k uložení každé poloviny a třetí se používá k uložení konečného tříděného seznamu. Každé pole se rekurzivně třídí. Nakonec se podjednotky sloučí, aby z něj byla n velikost prvku pole. Seznam byl vždy rozdělen na polovinu (n / 2) odlišnou od rychlého třídění.
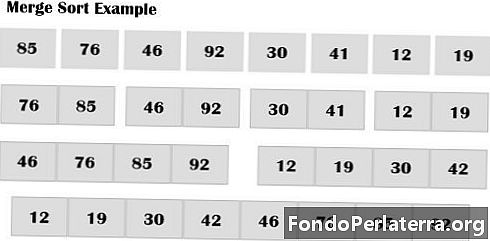
Nechť A je pole n počtu prvků, které mají být tříděny A, A, ………, A. Třídění slučování následuje dané kroky.
- Rozdělte matici A na přibližně n / 2 tříděné podpole po 2, což znamená, že prvky v (A, A), (A, A), (A, A), (A, A) dílčích polích musí být seřazené.
- Zkombinujte každou dvojici, abyste získali seznam tříděných dílčích polí velikosti 4; prvky v dílčích polích jsou také seřazené (A, A, A, A), ……, (A, A, A, A), ……., (A, A, A, A).
- Krok 2 se provádí opakovaně, dokud není k dispozici pouze jedno seřazené pole velikosti n.
Výhody a nevýhody
Algoritmus sloučení řazení funguje přesně a přesně bez ohledu na počet prvků zapojených do třídění. Funguje dobře iu velké sady dat. Spotřebuje však větší část paměti.
- Při sloučení se pole musí rozdělit na dvě poloviny (tj. N / 2). Naproti tomu v rychlém řazení neexistuje nutnost rozdělení seznamu na stejné prvky.
- Nejhorší složitost rychlého řazení je O (n2), protože to vyžaduje mnohem více srovnání v nejhorším stavu. Naproti tomu sloučené řazení má stejné nejhorší případy a průměrné složité případy, tj. O (n log n).
- Sloučit řazení může dobře fungovat na libovolném typu datových sad, ať už je velký nebo malý. Naopak, rychlé řazení nemůže dobře fungovat s velkými datovými soubory.
- Rychlé řazení je v některých případech rychlejší než sloučení, například pro malé datové sady.
- Sloučit řazení vyžaduje další paměťový prostor pro uložení pomocných polí. Na druhou stranu, rychlé řazení nevyžaduje více místa pro další úložiště.
- Sloučit řazení je efektivnější než rychlé řazení.
- Rychlé třídění je metoda interního třídění, kde se data, která mají být tříděna, upravují najednou v hlavní paměti. Naopak, sloučení třídění je metoda externího třídění, ve které data, která mají být tříděna, nemohou být uložena do paměti současně a některá musí být uchována v pomocné paměti.
Závěr
Rychlé řazení je rychlejší případy, ale v některých situacích je neefektivní a také provádí mnoho srovnání ve srovnání s sloučením. Přestože slučovací řazení vyžaduje menší srovnání, pro uložení dalšího pole potřebuje další paměťový prostor 0 (n), zatímco rychlé řazení potřebuje prostor O (log n).





